

Auth is hard to do well. Like, for realsies. It’s far from trivial but essential to get right. This is exactly the problem AWS Cognito aims to solve. In Amazon’s own words
Amazon Cognito lets you add user sign-up, sign-in, and access control to your web and mobile apps quickly and easily.
While there are many things that Cognito does extremely well, my experience with the popular service is anything less than quick or easy. In this post, I’ll briefly cover how Cognito works before describing a frustrating feature of this popular AWS service that may leave you questioning your very sanity.
Let’s dive in!
How Cognito Works
At the risk of oversimplifying, AWS Cognito exists to answer two questions:
- Who are you? (authentication)
- What can you do? (authorization)
Cognito addresses these concerns with two distinct offerings: User Pools (authentication) and Identity Pools (authorization).
User Pools
You can think of Cognito User Pools as your applications user directory. At a high level, User Pools let you handle user registration, authentication, account recovery, and supports authentication with third-party identity providers like Facebook, Google, etc.
Identity Pools
Cognito Identity Pools provides a way to authorize users to use various AWS services. You can think of it as a vending machine for handing out AWS credentials. For example, if you needed to give your users access to upload a file to an S3 bucket or to invoke an endpoint in API Gateway, you could do so with an Identity Pool.
Cognito In Action
The process of using Cognito User Pools and Identity Pools looks like this
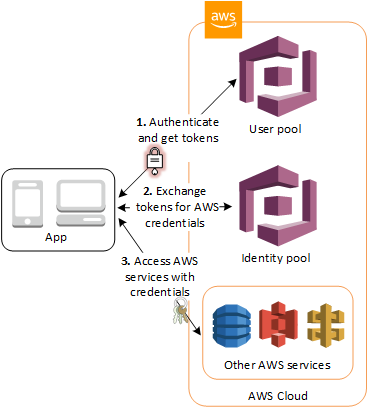
- Users sign-up and sign-in to your application via your Cognito User Pool.
- Your application fetches AWS credentials for your user.
- The logged in user can then use the credentials from step 2 to make calls to AWS resources (S3, API Gateway, etc)
I won’t cover how to implement each of these steps in this blog post. However, the fantastic AWS Amplify Framework has client SDKs and tutorials that make the implementation a breeze.
So What’s The Problem?
Under the covers, User pools and Identity Pools each use their own unique identifiers to track the same users identity. The problem is that AWS does not provide a mapping between these unique identifiers.
So what?
Recall that User Pools contain information about your user; email address, username, password, phone number, etc. User Pools do not know what permissions your users have.
Identity Pools contain information about user permissions; allow read access to an S3 bucket, allow access to invoke a specific API endpoint, etc. Identity Pools do not know specific user attributes.
Since AWS does not provide a mapping between User Pool IDs and Identity Pool IDs, you’ll be out of luck if when you need to relate user information (email address, username, phone number, etc) with a user action. This can be particularly problematic when you consider that AWS IAM policies exclusively use the users Identity Pool ID to uniquely identify the user.
Confusing, I know. But I’ll walk through an example of when this would be a problem.
S3 Private Folders
Imagine your application needs to allow users to upload a file to S3 that is only accessible to the individual user. You would start by defining the following IAM policy:
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:PutObject",
"s3:DeleteObject"
],
"Resource": [
"arn:aws:s3:::your-s3-bucket/${cognito-identity.amazonaws.com:sub}/*"
]
}
]
The ${cognito-identity.amazonaws.com:sub} is an IAM policy variable that resolves to the users’ unique identifier in the User Pool, also commonly called the users Cognito IdentityId.
This policy would allow authenticated users of your application the appropriate permissions to upload and delete files to a directory named after their Cognito IdentityId. Since the policy is specific to this user, this policy would not allow any other users to access the same folder. Hooray, a private upload solution!
However, since Cognito gives you no way to map the IdentityId back to the user, you have absolutely no idea which user owns this S3 bucket. This could pose a problem if you need to track a bug, provide user support for missing/failed uploads, track usage patterns for each user, etc.
This problem also pops up when working with Lambda proxy integrations in API Gateway. Depending on how your users authenticate with API Gateway, your Lambda either knows the IdentityId or the User Pool Id, never both! In each instance, having one is not sufficient to get the other.
Maddening!

The Solution
I’ll start with the bad news: there is no official AWS solution to this problem. The problem has been identified time and again through github issues dating as far back as 2017, insightful stackoverflow questions and answers and more Google results than you can shake a stick at. It’s extremely frustrating.
In short, you’ll need to maintain your own mapping between User Pool and Identity Pool information. Here are a few workarounds to consider.
A Client-Side Workaround
If you’re using AWS Amplify, getting a user’s Identity Id is not difficult.
import {Auth} from "aws-amplify";
const user = await Auth.signIn(username, password);
const credentials = await Auth.currentCredentials();
console.log('Cognito identity ID:', credentials.identityId);
Once you have the IdentityId, you can pass it to the backend for storage (e.g. DynamoDB). You could also save the IdentityId as a custom User Pool attribute
await Auth.updateUserAttributes(user, {
'custom:identity_id': credentials.identityId,
});
While this approach is simple, it relies on information that is sent from the client, which means it should not be relied upon without verification. Nevertheless, it’s a popular workaround due to its simplicity.
A Server-Side Workaround
If you are not satisfied with a client-side solution, you could follow the approach outlined in a github comment from a member of the AWS Cognito team:
- Add a custom attribute to your user pools schema called identityId
- Make it read-only to the client that your end users are authenticating with
- Authenticate the end-user
- Get AWS credentials for the end-user
- If there is no identity id present in the user profile, call a Lambda using the AWS credentials from step 4 and provide the id token from the end-user as a parameter.
- In the lambda call Cognito Federated Identity’s GetId and pass the id token for the end-user in the logins map, this will return the identity id
- In the lambda call AdminUpdateUser to set the IdentityId profile attribute to the value returned in step 6
- Optionally refresh the end users’ user pool tokens so they will have the identity id in them
While this solution is clever and addresses the client side limitation, I find it fairly complex. It relies on the application developer to do a lot of heavy lifting, which I believe should be handled for you within the SDK.
Conclusion
Cognito is an extremely powerful solution to a complex set of problems. However, the disconnect between User Pools and Identity Pools a massive shortcoming. What’s more frustrating, is that AWS has not been responsive to addressing this problem or offer an official workaround.
One of the benefits of using a service like Cognito is to increase developer velocity. Auth is hard and developers shouldn’t need to be security experts to integrate such a feature in their applications.
When it comes to Cognito, you can forget about being shielded from the details. You are going to need to roll up your sleeves and spend days wrapping your head around many complex topics. You may not need to know a lot about security, but you are going to need to know a lot about Cognito.
Comments